SNV Analysis Report
Overview
Reads Source: List of BioProject accessions
Total Samples: 8 samples
Results Directory: ../hcapsulatum/
Reference Host Genome: 2-alignment/host/genomes/Homo_sapiens_GRCh38/genome.fa
Reference Pathogen Genomes:
| Genome file | Protein file | Gene file |
|---|---|---|
| data/genome/genome.fa | data/genome/protein.fa | data/genome/genes.gbk |
Input Reads:
| ID | Type | File 1 | File 2 |
|---|---|---|---|
| SRR950197 | paired | data/fastq/SRR950197_1.fastq | data/fastq/SRR950197_2.fastq |
| SRR950198 | paired | data/fastq/SRR950198_1.fastq | data/fastq/SRR950198_2.fastq |
| SRR949916 | paired | data/fastq/SRR949916_1.fastq | data/fastq/SRR949916_2.fastq |
| SRR950093 | paired | data/fastq/SRR950093_1.fastq | data/fastq/SRR950093_2.fastq |
| SRR949601 | paired | data/fastq/SRR949601_1.fastq | data/fastq/SRR949601_2.fastq |
| SRR949624 | paired | data/fastq/SRR949624_1.fastq | data/fastq/SRR949624_2.fastq |
| SRR949060 | paired | data/fastq/SRR949060_1.fastq | data/fastq/SRR949060_2.fastq |
| SRR949270 | paired | data/fastq/SRR949270_1.fastq | data/fastq/SRR949270_2.fastq |
Read Quality
Quality Check
The quality check was done using FastQC (https://www.bioinformatics.babraham.ac.uk/projects/fastqc/). This tool analyzes the quality of all reads in fastq files and creates reports that help identify quality issues in high-throughput sequencing datasets. All the results were stored in 1-quality/fastqc.
Read Cropping
Read cropping was done using Trimmomatic (http://www.usadellab.org/cms/?page=trimmomatic). This tool preprocesses high-throughput sequencing data from next-generation sequencing platforms. It specializes in quality control and trimming of raw sequence reads, removing artifacts, adapters, and low-quality bases. When SNVGuru identifies that a read has a quality decay greater than 1.0, it crops the reads down to 100 base pairs. The cropped fastq files were stored in 1-quality/fastq.
Host Alignment
The reads were aligned against a host reference genome in order to remove reads belonging to the host instead of the pathogen, which could alter the results of the analysis. This alignment was done using STAR (https://github.com/alexdobin/STAR). This tool is a widely used RNA-seq read aligner for short and long reads, particularly well-suited for mapping reads to genomes with complex structures, such as those with many introns and alternative splicing events.. The initial alignments were stored in SAM format at 2-alignment/host/sam.
After doing this, the reads that did not align against the host reference genome were extracted using samtools (http://www.htslib.org/). First, it runs samtools view -F 256 on the SAM files, so that every sequence that aligned is ignored and the rest is saved in BAM files at 2-alignment/host/bam. Then, it runs samtools bam2fq on the resulting BAM files to transform them into fastq files. These filtered fastq files were stored at 2-alignment/host/fastq. The number of reads are the following:
| Sample | Reads Before Filter | Reads After Filter |
|---|---|---|
| SRR949060 | 4491958 | 4488169 |
| SRR949270 | 4976685 | 4972603 |
| SRR949601 | 5346164 | 5340436 |
| SRR949624 | 4463141 | 4459973 |
| SRR949916 | 7930327 | 7927817 |
| SRR950093 | 8465707 | 8458078 |
| SRR950197 | 8243759 | 8240716 |
| SRR950198 | 7575132 | 7562647 |
Pathogen Alignment
The reads were aligned against the provided reference pathogen genomes using HISAT2 (http://daehwankimlab.github.io/hisat2/). This tool is a widely used RNA-seq read aligner for short reads, particularly well-suited for ekaryotic transcriptomes with complex splicing patterns.. The initial alignments were stored in SAM format at 2-alignment/pathogen/sam. Then, using samtools (http://www.htslib.org/), the alignments were sorted and transformed into a BAM file running samtools sort, and finally, the MD and NM tags were added running samtools calmd. These resulting BAM files were stored at 2-alignment/pathogen/bam, where the .sorted.bam files are the result of samtools sort, and the .bam files are the final BAM files resulting from samtools calmd.
Alignment Quality
The alignments against the pathogen reference genome were analyzed using Qualimap 2 (http://qualimap.conesalab.org/). This tool inspects SAM/BAM files, analyzes the features of the mapped reads and generates a report of the aligned data. This helps detect issues in the sequencing and/or mapping of the data. The results were stored at 3-qualimap.
After the analysis is done, SNVGuru removes the samples that produced a general error rate greater than 3.0%. The error rates were the following:
| Reference pathogen | ID | Error rate (%) |
|---|---|---|
| genome | SRR950197 | 0.86 |
| genome | SRR950198 | 0.8 |
| genome | SRR949916 | 0.14 |
| genome | SRR950093 | 0.21 |
| genome | SRR949601 | 0.78 |
| genome | SRR949624 | 0.84 |
| genome | SRR949060 | 0.08 |
| genome | SRR949270 | 0.09 |
SNV Calling
The SNV calling step was performed using REDItools2 (https://github.com/BioinfoUNIBA/REDItools2) and JACUSA2 (https://github.com/dieterich-lab/JACUSA2).
REDItools2 is a toolkit designed for the analysis of RNA editing events in high-throughput sequencing data, identifying, quantifying, and characterizing RNA editing sites from RNA-seq data. It generates TXT files with the SNV data, which were transformed into VCF files, and these VCF files were also modified for using them as SnpEff inputs. These files were stored at 4-snvCalling/reditools. The files used for SnpEff are named as SAMPLE.reditools.presnpeff.vcf.
JACUSA2 is a framework for single nucleotide variant and reverse transcriptase induced arrest event detection in next-generation sequencing data. It generates VCF files with the SNV data, which were then preprocessed for using them as SnpEff inputs. These files were stored at 4-snvCalling/jacusa. The original output files are named as SAMPLE.jacusa.vcf. while the files used for SnpEff are named as SAMPLE.jacusa.presnpeff.vcf. There are also some files named as SAMPLE.jacusa.vcf.filtered and SAMPLE.jacusa.vcf.filtered.idx that are byproducts of the execution of the program.
Gene and Functional Effect Identification
For identifying the gene and functional effect of each SNV, the VCF files from the previous step were processed with SnpEff (http://pcingola.github.io/SnpEff/). It is a genetic variant annotation and functional effect prediction toolbox, particularly made for single nucleotide polymorphisms and small insertions/deletions. It categorizes variants based on their impact on genes, classifying them into different functional consequences such as synonymous, nonsynonymous, frameshift, and more. The output files of this tool were stored at 5-snpeff.
Allele-Specific Strand Odds Ratio Calculation
The computation of AS strand odds ratio (AS_SOR) was done executing BCFtools' (https://samtools.github.io/bcftools/) mpileup on each resulting BAM file from the alignment using the argument -a FORMAT/AD,FORMAT/ADF,FORMAT/ADR,FORMAT/DP,FORMAT/SP in order to get the allelic depth of the forward and reverse strands for both the reference and the aligned sequences. The output files are found at 4-snvCalling/depths/REFERENCE_NAME/SAMPLE_NAME.mpileup.vcf for each pathogen reference genome and sample pair.
Each output file's last column is named as the path of the respective BAM file. This column has a string that, when split by the colon (:) character, results in six fields. The fourth one is the allelic depth for the forward strand (ADF), and the fifth one is the allelic depth for the reverse strand (ARF). Both fields have two comma-separated values, where the first one corresponds to the reference allele and the second one corresponds to the alternate allele. This leaves us with four values: forward reference depth (FRD), reverse reference depth (RRD), forward alternate depth (FAD) and reverse alternate depth (RAD). The formula for calculating the AS_SOR, according to GATK (https://gatk.broadinstitute.org/hc/en-us/articles/4414586726683-AS-StrandOddsRatio) is as follows: $$AS\_SOR = {ln(\frac{FAD * RRD}{FRD * RAD}) + ln(\frac{min(FRD, RRD)}{max(FRD, RRD)}) - ln(\frac{min(FAD, RAD)}{max(FAD, RAD)})}$$ If a mutation has an AS_SOR > 4.0, then it is filtered out of the resulting files and graphs.
Results
Common Identified SNVs
This step merges the identified SNVs from JACUSA2 and REDItools2 by position and mutation (nucleotide change). If any combination of position and mutation is not found in either of the outputs, it is discarded. Furthermore, these SNVs are filtered by the following values:
- Minimum base quality: 35
- Minimum read quality: 25
- Minimum SNV coverage: 20
- Minimum main read support: 4
- Minimum SNV frequency: 0.0
These files were stored at 6-visualization/csv/globalCommon.csv for the global results among all samples, and 6-visualization/SAMPLE_NAME/csv/runCommon.csv for the results of each sample. There is also a file for the global results and for each sample of the results by JACUSA2 (6-visualization/REFERENCE_NAME/csv/globalJacusa.csv and 6-visualization/REFERENCE_NAME/SAMPLE_NAME/csv/jacusa.csv) and REDItools2 (6-visualization/csv/globalReditools.csv and 6-visualization/SAMPLE_NAME/csv/reditools.csv). Here is a sample from the global results file.
| CHROM | Position | Alt | Reference | Type | AAVar | GeneName | GeneID | RefReads | AltReads | TotalReads | Frequency | A | C | G | T | JacRefReads | JacAltReads | JacTotalReads | JacFrequency | JacA | JacC | JacG | JacT | Sample |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GG663363.1 | 151854 | T | C | synonymous_variant | p.Ala1200Ala | HCBG_00002 | HCBG_00002 | 0 | 57 | 57 | 100.0 | 0 | 0 | 0 | 57 | 0 | 69 | 69 | 100.0 | 0 | 0 | 0 | 69 | SRR950197 |
| GG663363.1 | 152070 | G | A | synonymous_variant | p.Pro1128Pro | HCBG_00002 | HCBG_00002 | 0 | 52 | 52 | 100.0 | 0 | 0 | 52 | 0 | 0 | 66 | 66 | 100.0 | 0 | 0 | 66 | 0 | SRR950197 |
| GG663363.1 | 152181 | T | C | synonymous_variant | p.Gln1091Gln | HCBG_00002 | HCBG_00002 | 0 | 23 | 23 | 100.0 | 0 | 0 | 0 | 23 | 0 | 26 | 26 | 100.0 | 0 | 0 | 0 | 26 | SRR950197 |
| GG663363.1 | 152324 | T | G | synonymous_variant | p.Arg1044Arg | HCBG_00002 | HCBG_00002 | 0 | 37 | 37 | 100.0 | 0 | 0 | 0 | 37 | 0 | 49 | 49 | 100.0 | 0 | 0 | 0 | 49 | SRR950197 |
| GG663363.1 | 152491 | A | G | synonymous_variant | p.Gly1010Gly | HCBG_00002 | HCBG_00002 | 0 | 44 | 44 | 100.0 | 44 | 0 | 0 | 0 | 0 | 64 | 64 | 100.0 | 64 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 152542 | A | G | synonymous_variant | p.Gly993Gly | HCBG_00002 | HCBG_00002 | 0 | 40 | 40 | 100.0 | 40 | 0 | 0 | 0 | 0 | 48 | 48 | 100.0 | 48 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 152641 | C | T | synonymous_variant | p.Thr960Thr | HCBG_00002 | HCBG_00002 | 0 | 41 | 41 | 100.0 | 0 | 41 | 0 | 0 | 0 | 53 | 53 | 100.0 | 0 | 53 | 0 | 0 | SRR950197 |
| GG663363.1 | 152749 | T | C | synonymous_variant | p.Gly924Gly | HCBG_00002 | HCBG_00002 | 0 | 29 | 29 | 100.0 | 0 | 0 | 0 | 29 | 0 | 41 | 41 | 100.0 | 0 | 0 | 0 | 41 | SRR950197 |
| GG663363.1 | 152878 | C | T | synonymous_variant | p.Val881Val | HCBG_00002 | HCBG_00002 | 0 | 22 | 22 | 100.0 | 0 | 22 | 0 | 0 | 0 | 36 | 36 | 100.0 | 0 | 36 | 0 | 0 | SRR950197 |
| GG663363.1 | 152947 | G | A | synonymous_variant | p.Ile858Ile | HCBG_00002 | HCBG_00002 | 0 | 51 | 51 | 100.0 | 0 | 0 | 51 | 0 | 0 | 74 | 74 | 100.0 | 0 | 0 | 74 | 0 | SRR950197 |
| GG663363.1 | 153096 | G | A | synonymous_variant | p.Asp834Asp | HCBG_00002 | HCBG_00002 | 0 | 37 | 37 | 100.0 | 0 | 0 | 37 | 0 | 0 | 50 | 50 | 100.0 | 0 | 0 | 50 | 0 | SRR950197 |
| GG663363.1 | 153210 | G | C | synonymous_variant | p.Thr796Thr | HCBG_00002 | HCBG_00002 | 0 | 24 | 24 | 100.0 | 0 | 0 | 24 | 0 | 0 | 28 | 28 | 100.0 | 0 | 0 | 28 | 0 | SRR950197 |
| GG663363.1 | 153267 | A | C | synonymous_variant | p.Ser777Ser | HCBG_00002 | HCBG_00002 | 0 | 29 | 29 | 100.0 | 29 | 0 | 0 | 0 | 0 | 39 | 39 | 100.0 | 39 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 153399 | T | C | synonymous_variant | p.Arg733Arg | HCBG_00002 | HCBG_00002 | 0 | 38 | 38 | 100.0 | 0 | 0 | 0 | 38 | 0 | 48 | 48 | 100.0 | 0 | 0 | 0 | 48 | SRR950197 |
| GG663363.1 | 153534 | C | T | synonymous_variant | p.Lys688Lys | HCBG_00002 | HCBG_00002 | 0 | 36 | 36 | 100.0 | 0 | 36 | 0 | 0 | 0 | 45 | 45 | 100.0 | 0 | 45 | 0 | 0 | SRR950197 |
| GG663363.1 | 153561 | G | A | synonymous_variant | p.Asp679Asp | HCBG_00002 | HCBG_00002 | 0 | 32 | 32 | 100.0 | 0 | 0 | 32 | 0 | 0 | 47 | 47 | 100.0 | 0 | 0 | 47 | 0 | SRR950197 |
| GG663363.1 | 153579 | A | G | synonymous_variant | p.Phe673Phe | HCBG_00002 | HCBG_00002 | 0 | 32 | 32 | 100.0 | 32 | 0 | 0 | 0 | 0 | 41 | 41 | 100.0 | 41 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 153687 | C | A | synonymous_variant | p.Thr637Thr | HCBG_00002 | HCBG_00002 | 0 | 25 | 25 | 100.0 | 0 | 25 | 0 | 0 | 0 | 37 | 37 | 100.0 | 0 | 37 | 0 | 0 | SRR950197 |
| GG663363.1 | 153735 | G | A | synonymous_variant | p.Asn621Asn | HCBG_00002 | HCBG_00002 | 0 | 47 | 47 | 100.0 | 0 | 0 | 47 | 0 | 0 | 53 | 53 | 100.0 | 0 | 0 | 53 | 0 | SRR950197 |
| GG663363.1 | 154206 | G | T | synonymous_variant | p.Gly464Gly | HCBG_00002 | HCBG_00002 | 0 | 26 | 26 | 100.0 | 0 | 0 | 26 | 0 | 0 | 34 | 34 | 100.0 | 0 | 0 | 34 | 0 | SRR950197 |
| GG663363.1 | 154236 | G | A | synonymous_variant | p.Pro454Pro | HCBG_00002 | HCBG_00002 | 0 | 27 | 27 | 100.0 | 0 | 0 | 27 | 0 | 0 | 37 | 37 | 100.0 | 0 | 0 | 37 | 0 | SRR950197 |
| GG663363.1 | 154339 | G | T | missense_variant | p.Asn420Thr | HCBG_00002 | HCBG_00002 | 0 | 31 | 31 | 100.0 | 0 | 0 | 31 | 0 | 0 | 35 | 35 | 100.0 | 0 | 0 | 35 | 0 | SRR950197 |
| GG663363.1 | 154626 | G | A | synonymous_variant | p.Gly324Gly | HCBG_00002 | HCBG_00002 | 0 | 24 | 24 | 100.0 | 0 | 0 | 24 | 0 | 0 | 40 | 40 | 100.0 | 0 | 0 | 40 | 0 | SRR950197 |
| GG663363.1 | 154692 | A | G | synonymous_variant | p.Ser302Ser | HCBG_00002 | HCBG_00002 | 0 | 27 | 27 | 100.0 | 27 | 0 | 0 | 0 | 0 | 38 | 38 | 100.0 | 38 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 154721 | C | T | missense_variant | p.Thr293Ala | HCBG_00002 | HCBG_00002 | 0 | 21 | 21 | 100.0 | 0 | 21 | 0 | 0 | 0 | 25 | 25 | 100.0 | 0 | 25 | 0 | 0 | SRR950197 |
| GG663363.1 | 154758 | A | G | synonymous_variant | p.Ala280Ala | HCBG_00002 | HCBG_00002 | 0 | 20 | 20 | 100.0 | 20 | 0 | 0 | 0 | 0 | 22 | 22 | 100.0 | 22 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 154963 | G | A | missense_variant | p.Leu212Pro | HCBG_00002 | HCBG_00002 | 0 | 26 | 26 | 100.0 | 0 | 0 | 26 | 0 | 0 | 33 | 33 | 100.0 | 0 | 0 | 33 | 0 | SRR950197 |
| GG663363.1 | 155004 | T | G | synonymous_variant | p.Pro198Pro | HCBG_00002 | HCBG_00002 | 0 | 24 | 24 | 100.0 | 0 | 0 | 0 | 24 | 0 | 28 | 28 | 100.0 | 0 | 0 | 0 | 28 | SRR950197 |
| GG663363.1 | 158108 | T | G | upstream_gene_variant | nan | HCBG_00002 | HCBG_00002 | 0 | 21 | 21 | 100.0 | 0 | 0 | 0 | 21 | 0 | 45 | 45 | 100.0 | 0 | 0 | 0 | 45 | SRR950197 |
| GG663363.1 | 158123 | A | G | upstream_gene_variant | nan | HCBG_00002 | HCBG_00002 | 0 | 27 | 27 | 100.0 | 27 | 0 | 0 | 0 | 0 | 70 | 70 | 100.0 | 70 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 158380 | T | C | synonymous_variant | p.Thr650Thr | HCBG_00004 | HCBG_00004 | 0 | 165 | 165 | 100.0 | 0 | 0 | 0 | 165 | 0 | 222 | 222 | 100.0 | 0 | 0 | 0 | 222 | SRR950197 |
| GG663363.1 | 158774 | T | C | synonymous_variant | p.Glu550Glu | HCBG_00004 | HCBG_00004 | 0 | 97 | 97 | 100.0 | 0 | 0 | 0 | 97 | 0 | 147 | 147 | 100.0 | 0 | 0 | 0 | 147 | SRR950197 |
| GG663363.1 | 158889 | G | T | missense_variant | p.Asp512Ala | HCBG_00004 | HCBG_00004 | 0 | 48 | 48 | 100.0 | 0 | 0 | 48 | 0 | 0 | 64 | 64 | 100.0 | 0 | 0 | 64 | 0 | SRR950197 |
| GG663363.1 | 158894 | T | C | missense_variant | p.Met510Ile | HCBG_00004 | HCBG_00004 | 0 | 24 | 24 | 100.0 | 0 | 0 | 0 | 24 | 0 | 54 | 54 | 100.0 | 0 | 0 | 0 | 54 | SRR950197 |
| GG663363.1 | 159003 | G | A | missense_variant | p.Val474Ala | HCBG_00004 | HCBG_00004 | 0 | 29 | 29 | 100.0 | 0 | 0 | 29 | 0 | 0 | 66 | 66 | 100.0 | 0 | 0 | 66 | 0 | SRR950197 |
| GG663363.1 | 159076 | G | C | missense_variant | p.Val450Leu | HCBG_00004 | HCBG_00004 | 0 | 25 | 25 | 100.0 | 0 | 0 | 25 | 0 | 0 | 35 | 35 | 100.0 | 0 | 0 | 35 | 0 | SRR950197 |
| GG663363.1 | 159093 | A | C | missense_variant | p.Gly444Val | HCBG_00004 | HCBG_00004 | 0 | 28 | 28 | 100.0 | 28 | 0 | 0 | 0 | 0 | 52 | 52 | 100.0 | 52 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 159236 | C | T | synonymous_variant | p.Thr396Thr | HCBG_00004 | HCBG_00004 | 0 | 79 | 79 | 100.0 | 0 | 79 | 0 | 0 | 0 | 130 | 130 | 100.0 | 0 | 130 | 0 | 0 | SRR950197 |
| GG663363.1 | 159403 | C | T | synonymous_variant | p.Leu361Leu | HCBG_00004 | HCBG_00004 | 0 | 90 | 90 | 100.0 | 0 | 90 | 0 | 0 | 0 | 120 | 120 | 100.0 | 0 | 120 | 0 | 0 | SRR950197 |
| GG663363.1 | 159439 | A | G | synonymous_variant | p.Ser349Ser | HCBG_00004 | HCBG_00004 | 0 | 74 | 74 | 100.0 | 74 | 0 | 0 | 0 | 0 | 122 | 122 | 100.0 | 122 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 159454 | A | G | synonymous_variant | p.Ser344Ser | HCBG_00004 | HCBG_00004 | 0 | 77 | 77 | 100.0 | 77 | 0 | 0 | 0 | 2 | 117 | 119 | 98.3193 | 117 | 0 | 2 | 0 | SRR950197 |
| GG663363.1 | 159529 | A | T | missense_variant | p.Gln319His | HCBG_00004 | HCBG_00004 | 0 | 85 | 85 | 100.0 | 85 | 0 | 0 | 0 | 0 | 116 | 116 | 100.0 | 116 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 159574 | T | C | splice_region_variant&synonymous_variant | p.Leu304Leu | HCBG_00004 | HCBG_00004 | 0 | 51 | 52 | 100.0 | 0 | 0 | 1 | 51 | 0 | 65 | 66 | 100.0 | 0 | 0 | 1 | 65 | SRR950197 |
| GG663363.1 | 159574 | T | C | missense_variant&splice_region_variant | p.Leu304Phe | HCBG_00004 | HCBG_00004 | 0 | 51 | 52 | 100.0 | 0 | 0 | 1 | 51 | 0 | 65 | 66 | 100.0 | 0 | 0 | 1 | 65 | SRR950197 |
| GG663363.1 | 159653 | A | G | synonymous_variant | p.Arg302Arg | HCBG_00004 | HCBG_00004 | 0 | 37 | 37 | 100.0 | 37 | 0 | 0 | 0 | 0 | 54 | 54 | 100.0 | 54 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 159698 | G | A | synonymous_variant | p.Asn287Asn | HCBG_00004 | HCBG_00004 | 0 | 56 | 56 | 100.0 | 0 | 0 | 56 | 0 | 0 | 83 | 83 | 100.0 | 0 | 0 | 83 | 0 | SRR950197 |
| GG663363.1 | 159784 | A | G | synonymous_variant | p.Leu259Leu | HCBG_00004 | HCBG_00004 | 0 | 59 | 59 | 100.0 | 59 | 0 | 0 | 0 | 0 | 75 | 75 | 100.0 | 75 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 159871 | T | C | missense_variant | p.Val230Ile | HCBG_00004 | HCBG_00004 | 0 | 105 | 105 | 100.0 | 0 | 0 | 0 | 105 | 0 | 138 | 138 | 100.0 | 0 | 0 | 0 | 138 | SRR950197 |
| GG663363.1 | 160034 | T | A | missense_variant | p.Asn175Lys | HCBG_00004 | HCBG_00004 | 0 | 99 | 99 | 100.0 | 0 | 0 | 0 | 99 | 0 | 139 | 139 | 100.0 | 0 | 0 | 0 | 139 | SRR950197 |
| GG663363.1 | 160064 | A | G | synonymous_variant | p.Ala165Ala | HCBG_00004 | HCBG_00004 | 0 | 143 | 143 | 100.0 | 143 | 0 | 0 | 0 | 0 | 182 | 182 | 100.0 | 182 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 160142 | A | C | synonymous_variant | p.Leu139Leu | HCBG_00004 | HCBG_00004 | 0 | 75 | 75 | 100.0 | 75 | 0 | 0 | 0 | 0 | 84 | 84 | 100.0 | 84 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 160148 | C | T | synonymous_variant | p.Ser137Ser | HCBG_00004 | HCBG_00004 | 0 | 61 | 61 | 100.0 | 0 | 61 | 0 | 0 | 0 | 89 | 89 | 100.0 | 0 | 89 | 0 | 0 | SRR950197 |
| GG663363.1 | 160175 | A | G | synonymous_variant | p.His128His | HCBG_00004 | HCBG_00004 | 0 | 76 | 76 | 100.0 | 76 | 0 | 0 | 0 | 0 | 103 | 103 | 100.0 | 103 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 160229 | C | T | synonymous_variant | p.Thr110Thr | HCBG_00004 | HCBG_00004 | 0 | 84 | 84 | 100.0 | 0 | 84 | 0 | 0 | 0 | 128 | 128 | 100.0 | 0 | 128 | 0 | 0 | SRR950197 |
| GG663363.1 | 160432 | T | G | synonymous_variant | p.Ile67Ile | HCBG_00004 | HCBG_00004 | 0 | 50 | 50 | 100.0 | 0 | 0 | 0 | 50 | 0 | 78 | 78 | 100.0 | 0 | 0 | 0 | 78 | SRR950197 |
| GG663363.1 | 160447 | A | G | synonymous_variant | p.Asp62Asp | HCBG_00004 | HCBG_00004 | 0 | 35 | 35 | 100.0 | 35 | 0 | 0 | 0 | 0 | 70 | 70 | 100.0 | 70 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 160461 | G | A | synonymous_variant | p.Leu58Leu | HCBG_00004 | HCBG_00004 | 0 | 62 | 62 | 100.0 | 0 | 0 | 62 | 0 | 0 | 78 | 78 | 100.0 | 0 | 0 | 78 | 0 | SRR950197 |
| GG663363.1 | 160581 | G | A | upstream_gene_variant | nan | HCBG_00002 | HCBG_00002 | 0 | 70 | 70 | 100.0 | 0 | 0 | 70 | 0 | 0 | 84 | 84 | 100.0 | 0 | 0 | 84 | 0 | SRR950197 |
| GG663363.1 | 160737 | C | G | downstream_gene_variant | nan | HCBG_00003 | HCBG_00003 | 0 | 20 | 20 | 100.0 | 0 | 20 | 0 | 0 | 0 | 24 | 24 | 100.0 | 0 | 24 | 0 | 0 | SRR950197 |
| GG663363.1 | 160900 | G | A | synonymous_variant | p.Arg45Arg | HCBG_00004 | HCBG_00004 | 0 | 67 | 67 | 100.0 | 0 | 0 | 67 | 0 | 0 | 93 | 93 | 100.0 | 0 | 0 | 93 | 0 | SRR950197 |
| GG663363.1 | 161011 | T | C | synonymous_variant | p.Ala8Ala | HCBG_00004 | HCBG_00004 | 0 | 48 | 48 | 100.0 | 0 | 0 | 0 | 48 | 0 | 120 | 120 | 100.0 | 0 | 0 | 0 | 120 | SRR950197 |
| GG663363.1 | 161127 | C | T | upstream_gene_variant | nan | HCBG_00004 | HCBG_00004 | 0 | 27 | 27 | 100.0 | 0 | 27 | 0 | 0 | 0 | 45 | 45 | 100.0 | 0 | 45 | 0 | 0 | SRR950197 |
| GG663363.1 | 161235 | A | G | upstream_gene_variant | nan | HCBG_00004 | HCBG_00004 | 0 | 79 | 79 | 100.0 | 79 | 0 | 0 | 0 | 0 | 127 | 127 | 100.0 | 127 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 161291 | C | A | upstream_gene_variant | nan | HCBG_00004 | HCBG_00004 | 0 | 51 | 51 | 100.0 | 0 | 51 | 0 | 0 | 0 | 87 | 87 | 100.0 | 0 | 87 | 0 | 0 | SRR950197 |
| GG663363.1 | 161354 | G | A | upstream_gene_variant | nan | HCBG_00004 | HCBG_00004 | 0 | 29 | 29 | 100.0 | 0 | 0 | 29 | 0 | 0 | 49 | 49 | 100.0 | 0 | 0 | 49 | 0 | SRR950197 |
| GG663363.1 | 161522 | C | A | upstream_gene_variant | nan | HCBG_00004 | HCBG_00004 | 0 | 32 | 32 | 100.0 | 0 | 32 | 0 | 0 | 0 | 55 | 55 | 100.0 | 0 | 55 | 0 | 0 | SRR950197 |
| GG663363.1 | 170985 | G | A | synonymous_variant | p.Ala1409Ala | HCBG_00007 | HCBG_00007 | 0 | 20 | 20 | 100.0 | 0 | 0 | 20 | 0 | 0 | 25 | 25 | 100.0 | 0 | 0 | 25 | 0 | SRR950197 |
| GG663363.1 | 181517 | T | C | missense_variant | p.Arg232Lys | HCBG_00010 | HCBG_00010 | 0 | 31 | 31 | 100.0 | 0 | 0 | 0 | 31 | 0 | 55 | 55 | 100.0 | 0 | 0 | 0 | 55 | SRR950197 |
| GG663363.1 | 181537 | G | A | synonymous_variant | p.Gly225Gly | HCBG_00010 | HCBG_00010 | 0 | 58 | 58 | 100.0 | 0 | 0 | 58 | 0 | 0 | 106 | 106 | 100.0 | 0 | 0 | 106 | 0 | SRR950197 |
| GG663363.1 | 181585 | A | T | synonymous_variant | p.Ala209Ala | HCBG_00010 | HCBG_00010 | 0 | 66 | 66 | 100.0 | 66 | 0 | 0 | 0 | 0 | 164 | 164 | 100.0 | 164 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 181642 | A | G | synonymous_variant | p.Asp190Asp | HCBG_00010 | HCBG_00010 | 0 | 106 | 106 | 100.0 | 106 | 0 | 0 | 0 | 0 | 192 | 192 | 100.0 | 192 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 181658 | C | T | missense_variant | p.Asp185Gly | HCBG_00010 | HCBG_00010 | 0 | 96 | 96 | 100.0 | 0 | 96 | 0 | 0 | 0 | 177 | 177 | 100.0 | 0 | 177 | 0 | 0 | SRR950197 |
| GG663363.1 | 181717 | A | G | synonymous_variant | p.Gly165Gly | HCBG_00010 | HCBG_00010 | 0 | 43 | 43 | 100.0 | 43 | 0 | 0 | 0 | 0 | 53 | 53 | 100.0 | 53 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 181727 | G | T | missense_variant | p.Lys162Thr | HCBG_00010 | HCBG_00010 | 0 | 43 | 43 | 100.0 | 0 | 0 | 43 | 0 | 0 | 54 | 54 | 100.0 | 0 | 0 | 54 | 0 | SRR950197 |
| GG663363.1 | 181729 | T | A | missense_variant | p.Asp161Glu | HCBG_00010 | HCBG_00010 | 0 | 47 | 47 | 100.0 | 0 | 0 | 0 | 47 | 0 | 56 | 56 | 100.0 | 0 | 0 | 0 | 56 | SRR950197 |
| GG663363.1 | 181773 | C | T | missense_variant | p.Ile147Val | HCBG_00010 | HCBG_00010 | 0 | 36 | 36 | 100.0 | 0 | 36 | 0 | 0 | 0 | 64 | 64 | 100.0 | 0 | 64 | 0 | 0 | SRR950197 |
| GG663363.1 | 181888 | A | T | synonymous_variant | p.Thr108Thr | HCBG_00010 | HCBG_00010 | 0 | 102 | 102 | 100.0 | 102 | 0 | 0 | 0 | 0 | 154 | 154 | 100.0 | 154 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 182050 | G | A | missense_variant | p.Leu78Pro | HCBG_00010 | HCBG_00010 | 0 | 76 | 76 | 100.0 | 0 | 0 | 76 | 0 | 0 | 113 | 113 | 100.0 | 0 | 0 | 113 | 0 | SRR950197 |
| GG663363.1 | 191454 | C | T | synonymous_variant | p.Ala6Ala | HCBG_00014 | HCBG_00014 | 0 | 32 | 32 | 100.0 | 0 | 32 | 0 | 0 | 0 | 69 | 69 | 100.0 | 0 | 69 | 0 | 0 | SRR950197 |
| GG663363.1 | 191718 | T | C | synonymous_variant | p.Ala52Ala | HCBG_00014 | HCBG_00014 | 0 | 109 | 109 | 100.0 | 0 | 0 | 0 | 109 | 0 | 164 | 164 | 100.0 | 0 | 0 | 0 | 164 | SRR950197 |
| GG663363.1 | 191817 | A | G | synonymous_variant | p.Gln64Gln | HCBG_00014 | HCBG_00014 | 0 | 122 | 122 | 100.0 | 122 | 0 | 0 | 0 | 0 | 172 | 172 | 100.0 | 172 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 191827 | T | C | synonymous_variant | p.Leu68Leu | HCBG_00014 | HCBG_00014 | 0 | 115 | 115 | 100.0 | 0 | 0 | 0 | 115 | 0 | 175 | 176 | 100.0 | 0 | 0 | 1 | 175 | SRR950197 |
| GG663363.1 | 191904 | C | A | synonymous_variant | p.Leu93Leu | HCBG_00014 | HCBG_00014 | 0 | 81 | 81 | 100.0 | 0 | 81 | 0 | 0 | 0 | 142 | 142 | 100.0 | 0 | 142 | 0 | 0 | SRR950197 |
| GG663363.1 | 191913 | T | C | synonymous_variant | p.Pro96Pro | HCBG_00014 | HCBG_00014 | 0 | 115 | 115 | 100.0 | 0 | 0 | 0 | 115 | 0 | 184 | 184 | 100.0 | 0 | 0 | 0 | 184 | SRR950197 |
| GG663363.1 | 192006 | C | T | synonymous_variant | p.Leu127Leu | HCBG_00014 | HCBG_00014 | 1 | 58 | 59 | 98.3051 | 0 | 58 | 0 | 1 | 1 | 80 | 81 | 98.7654 | 0 | 80 | 0 | 1 | SRR950197 |
| GG663363.1 | 192018 | G | A | synonymous_variant | p.Arg131Arg | HCBG_00014 | HCBG_00014 | 1 | 40 | 41 | 97.561 | 1 | 0 | 40 | 0 | 1 | 54 | 55 | 98.1818 | 1 | 0 | 54 | 0 | SRR950197 |
| GG663363.1 | 192021 | A | G | synonymous_variant | p.Gly132Gly | HCBG_00014 | HCBG_00014 | 1 | 25 | 26 | 96.1538 | 25 | 0 | 1 | 0 | 1 | 40 | 41 | 97.561 | 40 | 0 | 1 | 0 | SRR950197 |
| GG663363.1 | 192042 | T | C | synonymous_variant | p.Asn139Asn | HCBG_00014 | HCBG_00014 | 1 | 100 | 101 | 99.0099 | 0 | 1 | 0 | 100 | 1 | 168 | 169 | 99.4083 | 0 | 1 | 0 | 168 | SRR950197 |
| GG663363.1 | 192391 | C | T | synonymous_variant | p.Gly190Gly | HCBG_00014 | HCBG_00014 | 0 | 253 | 253 | 100.0 | 0 | 253 | 0 | 0 | 1 | 316 | 317 | 99.6845 | 0 | 316 | 0 | 1 | SRR950197 |
| GG663363.1 | 192655 | C | T | upstream_gene_variant | nan | HCBG_00012 | HCBG_00012 | 0 | 22 | 22 | 100.0 | 0 | 22 | 0 | 0 | 0 | 45 | 45 | 100.0 | 0 | 45 | 0 | 0 | SRR950197 |
| GG663363.1 | 193462 | G | A | synonymous_variant | p.Ala2Ala | HCBG_00015 | HCBG_00015 | 0 | 55 | 55 | 100.0 | 0 | 0 | 55 | 0 | 0 | 73 | 73 | 100.0 | 0 | 0 | 73 | 0 | SRR950197 |
| GG663363.1 | 193528 | A | C | synonymous_variant | p.Ser24Ser | HCBG_00015 | HCBG_00015 | 0 | 51 | 51 | 100.0 | 51 | 0 | 0 | 0 | 0 | 108 | 108 | 100.0 | 108 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 193570 | C | T | synonymous_variant | p.Pro38Pro | HCBG_00015 | HCBG_00015 | 0 | 56 | 56 | 100.0 | 0 | 56 | 0 | 0 | 0 | 104 | 104 | 100.0 | 0 | 104 | 0 | 0 | SRR950197 |
| GG663363.1 | 193660 | T | C | synonymous_variant | p.His68His | HCBG_00015 | HCBG_00015 | 0 | 80 | 80 | 100.0 | 0 | 0 | 0 | 80 | 0 | 113 | 113 | 100.0 | 0 | 0 | 0 | 113 | SRR950197 |
| GG663363.1 | 193739 | C | A | missense_variant | p.Ser95Arg | HCBG_00015 | HCBG_00015 | 0 | 119 | 119 | 100.0 | 0 | 119 | 0 | 0 | 0 | 133 | 133 | 100.0 | 0 | 133 | 0 | 0 | SRR950197 |
| GG663363.1 | 194134 | T | C | synonymous_variant | p.Ser194Ser | HCBG_00015 | HCBG_00015 | 0 | 84 | 84 | 100.0 | 0 | 0 | 0 | 84 | 0 | 103 | 104 | 100.0 | 0 | 0 | 1 | 103 | SRR950197 |
| GG663363.1 | 194251 | A | G | synonymous_variant | p.Gln233Gln | HCBG_00015 | HCBG_00015 | 0 | 93 | 93 | 100.0 | 93 | 0 | 0 | 0 | 0 | 122 | 122 | 100.0 | 122 | 0 | 0 | 0 | SRR950197 |
| GG663363.1 | 194308 | T | C | synonymous_variant | p.Asn252Asn | HCBG_00015 | HCBG_00015 | 0 | 134 | 134 | 100.0 | 0 | 0 | 0 | 134 | 0 | 151 | 151 | 100.0 | 0 | 0 | 0 | 151 | SRR950197 |
| GG663363.1 | 194611 | G | A | upstream_gene_variant | nan | HCBG_00017 | HCBG_00017 | 0 | 20 | 20 | 100.0 | 0 | 0 | 20 | 0 | 0 | 35 | 35 | 100.0 | 0 | 0 | 35 | 0 | SRR950197 |
| GG663363.1 | 204570 | T | C | synonymous_variant | p.Thr592Thr | HCBG_00019 | HCBG_00019 | 0 | 22 | 22 | 100.0 | 0 | 0 | 0 | 22 | 0 | 30 | 30 | 100.0 | 0 | 0 | 0 | 30 | SRR950197 |
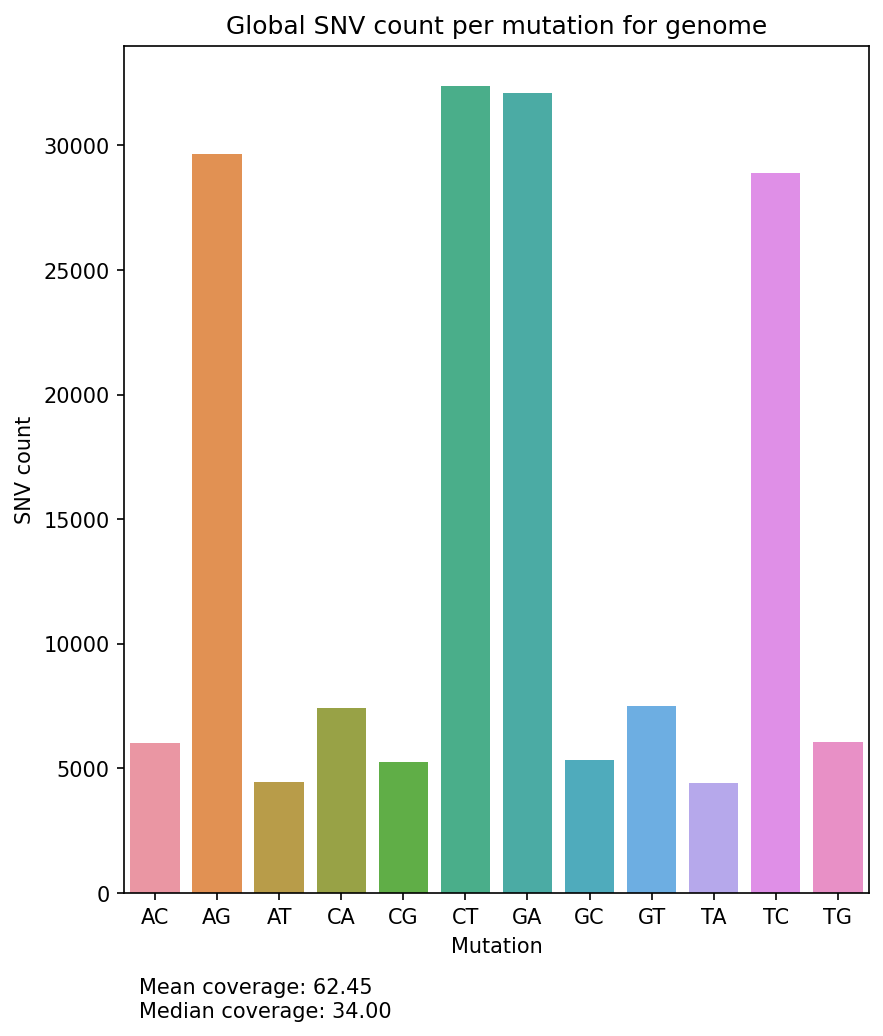
Mutation Count Bar Plot
Each sample has its own mutation count bar plot, as well as each reference pathogen genome has its own global mutation count bar plot. For each possible mutation, it counts how many times the mutation happened among all reads, regardless of the position, and plots it as a bar. It also displays the mean coverage and median coverage, where the coverage is the number of reads with alternate allele. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/common.mutationCountBarPlot.png for each reference genome graph, or 6-visualization/REFERENCE_NAME/SAMPLE_NAME/graphs/common.mutationCountBarPlot.png for each sample.
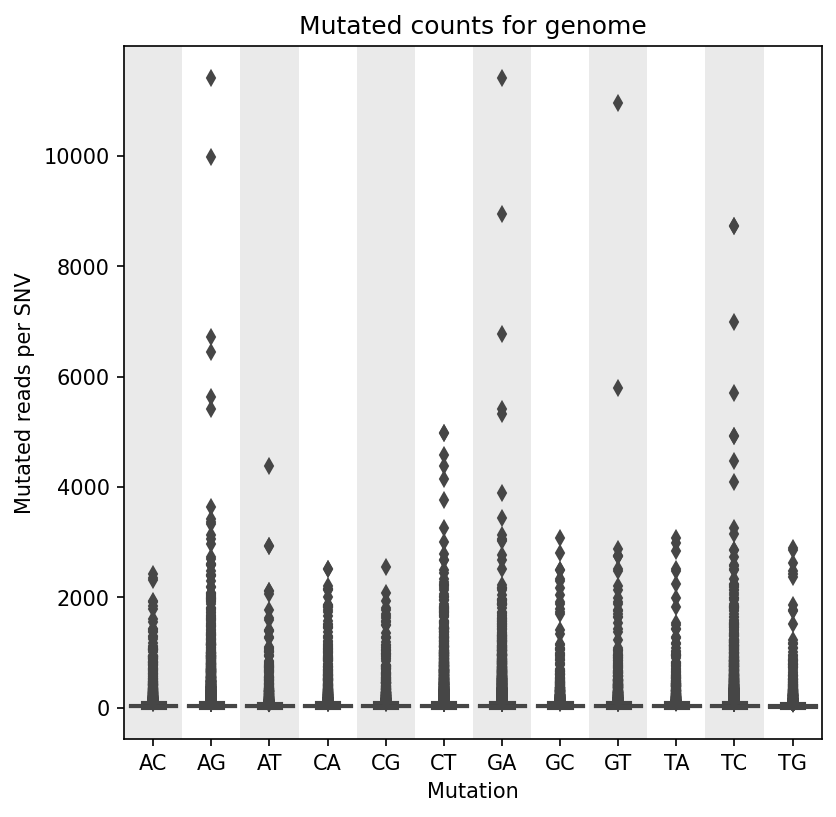
Mutation Count Box Plot
Each sample has its own mutation count box plot, as well as each reference pathogen genome has its own global mutation count box plot. For each possible mutation, it plots the box plot regardless of the position. It is possible to have many outliers, hence the graph can look like a dot plot with a small box in the bottom side. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/common.mutationCountBoxPlot.png for each reference genome graph, or 6-visualization/REFERENCE_NAME/SAMPLE_NAME/graphs/common.mutationCountBoxPlot.png for each sample.
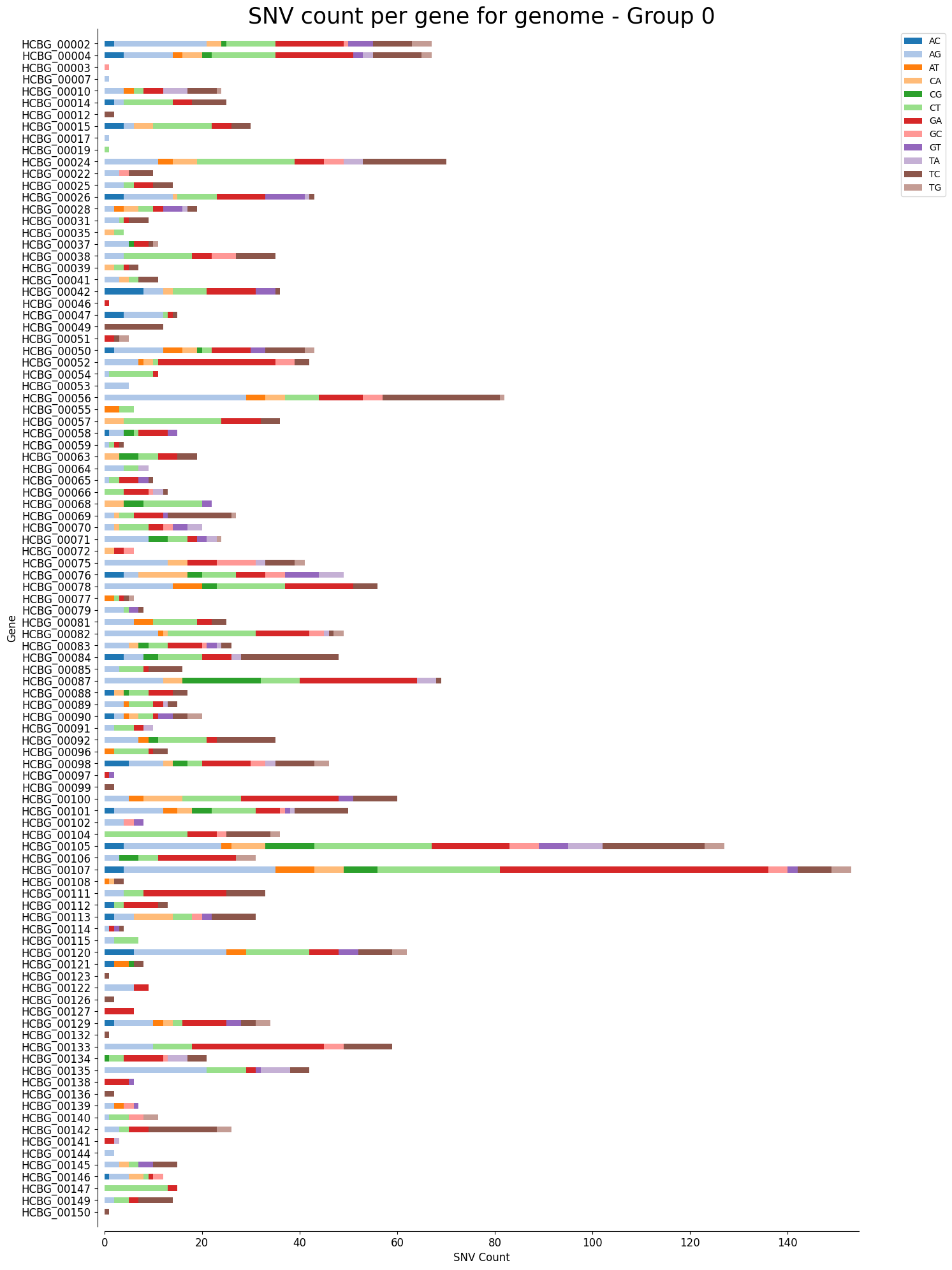
Mutation Count Stacked Bar Plot Per Gene
Each sample has its own mutation count stacked bar plot per gene, as well as each reference pathogen genome has its own global mutation count stacked bar plot per gene. For each gene, it plots a stacked bar, split by each possible mutation, where the length of each bar section is given by the number of reads that mutation has in that gene. It is possible that there are multiple graphs for each sample or reference pathogen. This is because it plots at most 100 genes per file, each file representing a group number. The genes are displayed ordered as they appear in the genome. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/geneBarPlot for each reference genome graph, or 6-visualization/REFERENCE_NAME/SAMPLE_NAME/graphs/geneBarPlot for each sample. There is also a file named _groups.txt where it says the group number of each gene.
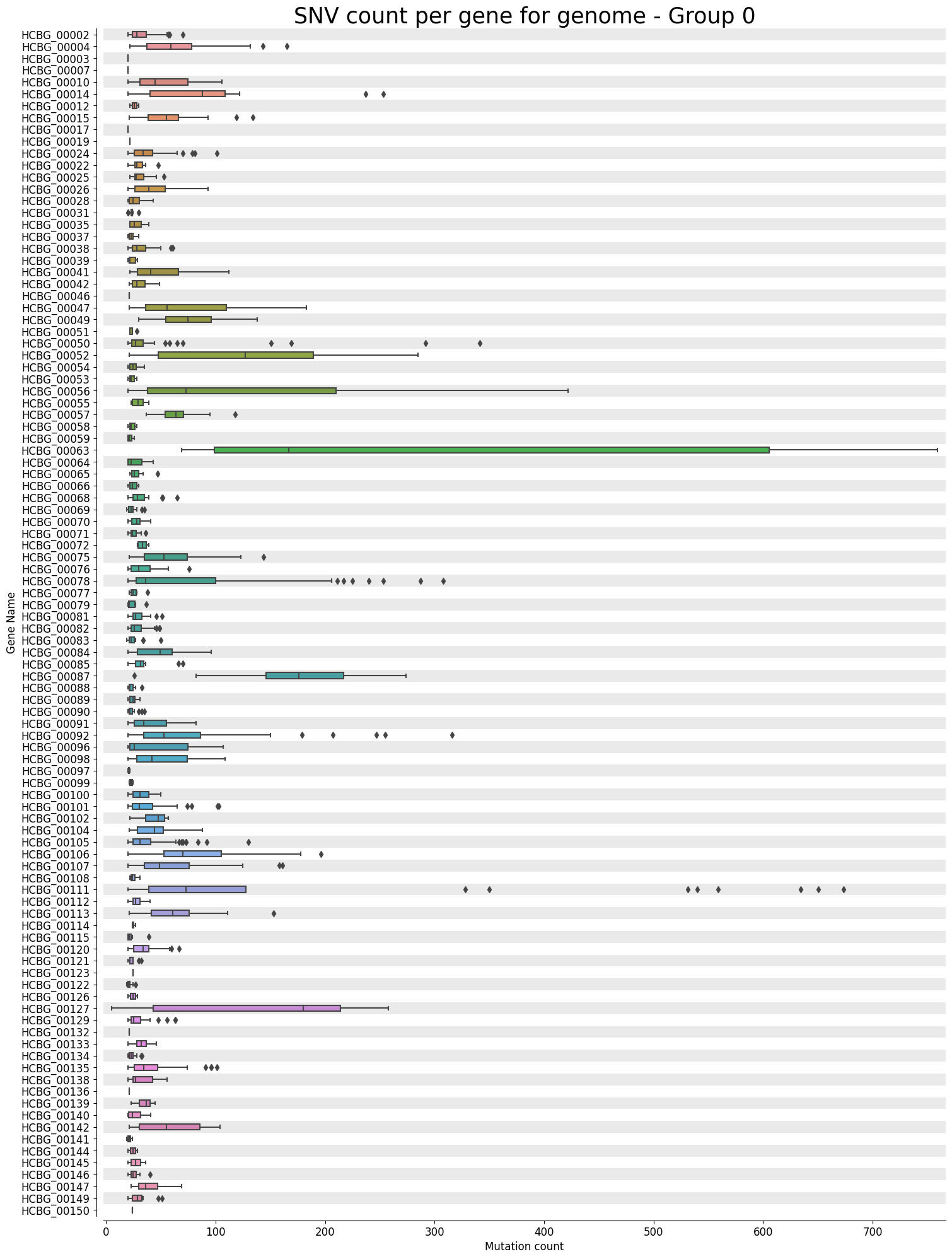
Mutation Count Box Plot Per Gene
Each sample has its own mutation count box plot per gene, as well as each reference pathogen genome has its own global mutation count box plot per gene. For each gene, it plots a box plot based on the number of mutated reads in that gene across all the different positions. Some box plots might have many outliers, so they can look like dot plots with a small box in the left side. It is possible that there are multiple graphs for each sample or reference pathogen. This is because it plots at most 100 genes per file, each file representing a group number. The genes are displayed ordered as they appear in the genome. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/geneBoxPlot for each reference genome graph, or 6-visualization/REFERENCE_NAME/SAMPLE_NAME/graphs/geneBoxPlot for each sample. There is also a file named _groups.txt where it says the group number of each gene.
Mutation Count Per Sample Bar Plot
Each reference pathogen genome has its own global mutation count per sample bar plot. For each possible mutation, it counts how many times the mutation happened among all reads in each sample, regardless of the position, and plots it as a bar. Each sample has its own bar. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/common.mutationsPerRunCountBarPlot.png for each reference genome graph.
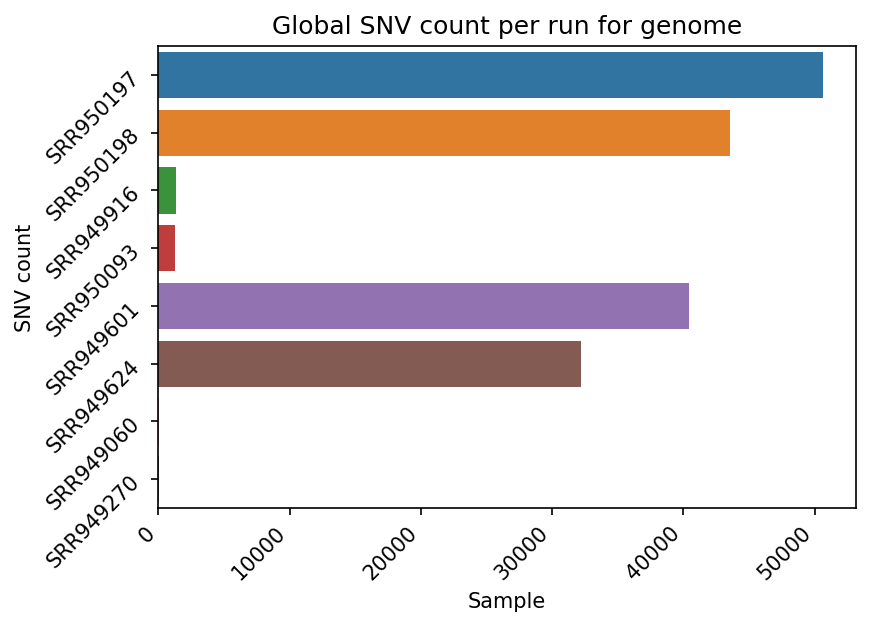
Mutation Count Per Sample Box Plot
Each reference pathogen genome has its own global mutation count per sample bar plot. For each sample, it plots a box plot based on the number of mutated reads in that sample across all the different positions. Some box plots might have many outliers, so they can look like dot plots with a small box in the left side. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/common.mutationsPerRunCountBoxPlot.png for each reference genome graph.
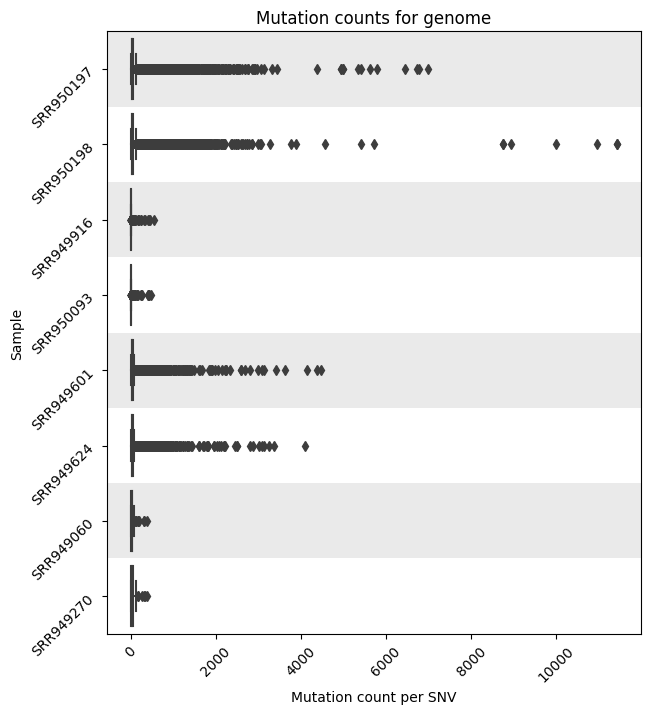
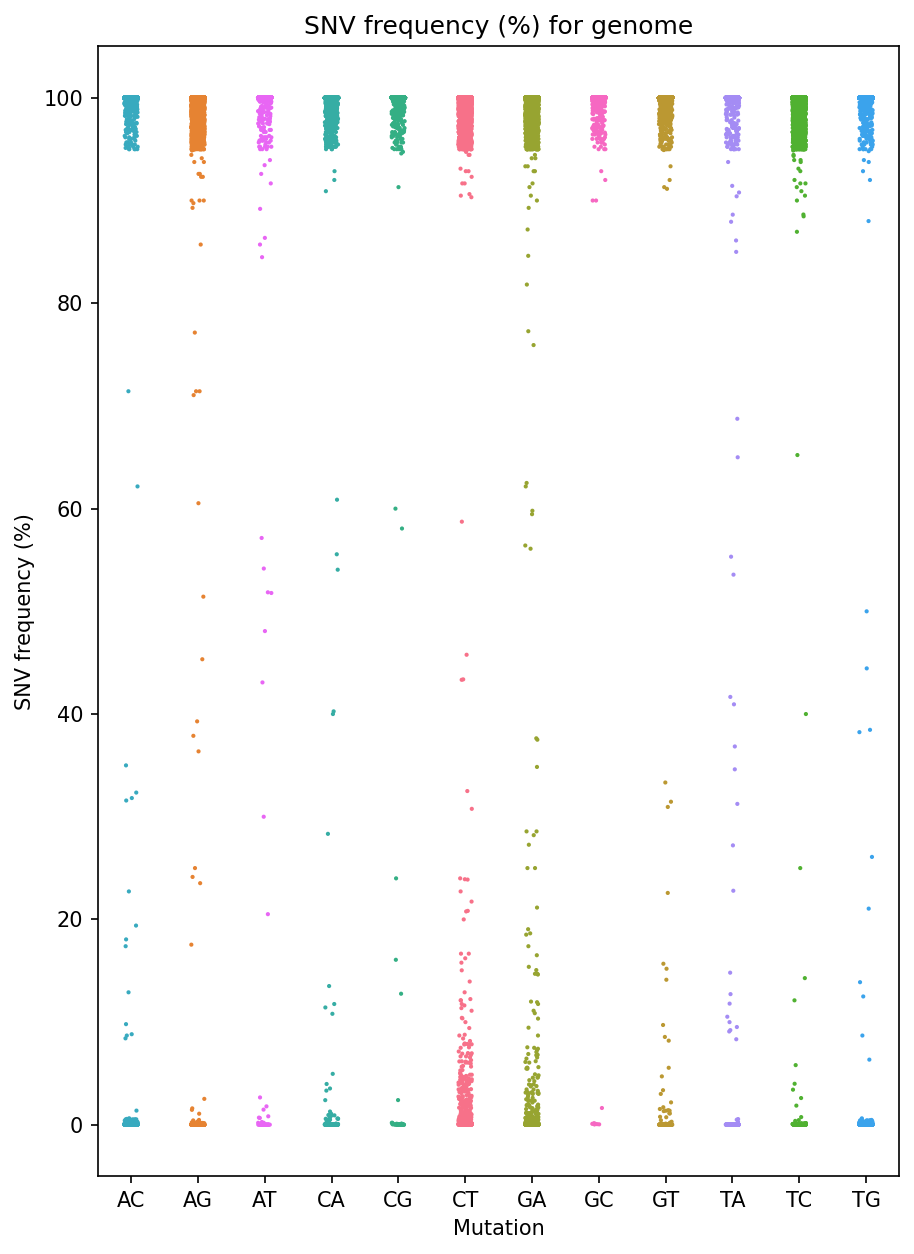
Frequency Per Mutation Strip Plot
Each reference pathogen genome has its own frequency per mnutation strip plot. It plots a strip plot, where each dot is the frequency of an SNV, and it appears in the strip of their respective mutation. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/common.frequencyPerMutation.png for each reference genome graph.
Frequency Per Gene Strip Plot
Each reference pathogen genome has its own frequency per gene strip plot. It plots a strip plot, where each dot is the frequency of an SNV, and it appears in the strip of their respective gene. It is possible that there are multiple graphs for each sample or reference pathogen. This is because it plots at most 100 genes per file, each file representing a group number. The genes are displayed ordered as they appear in the genome. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/common.frequencyPerMutation.png for each reference genome graph. There is also a file named _groups.txt where it says the group number of each gene.

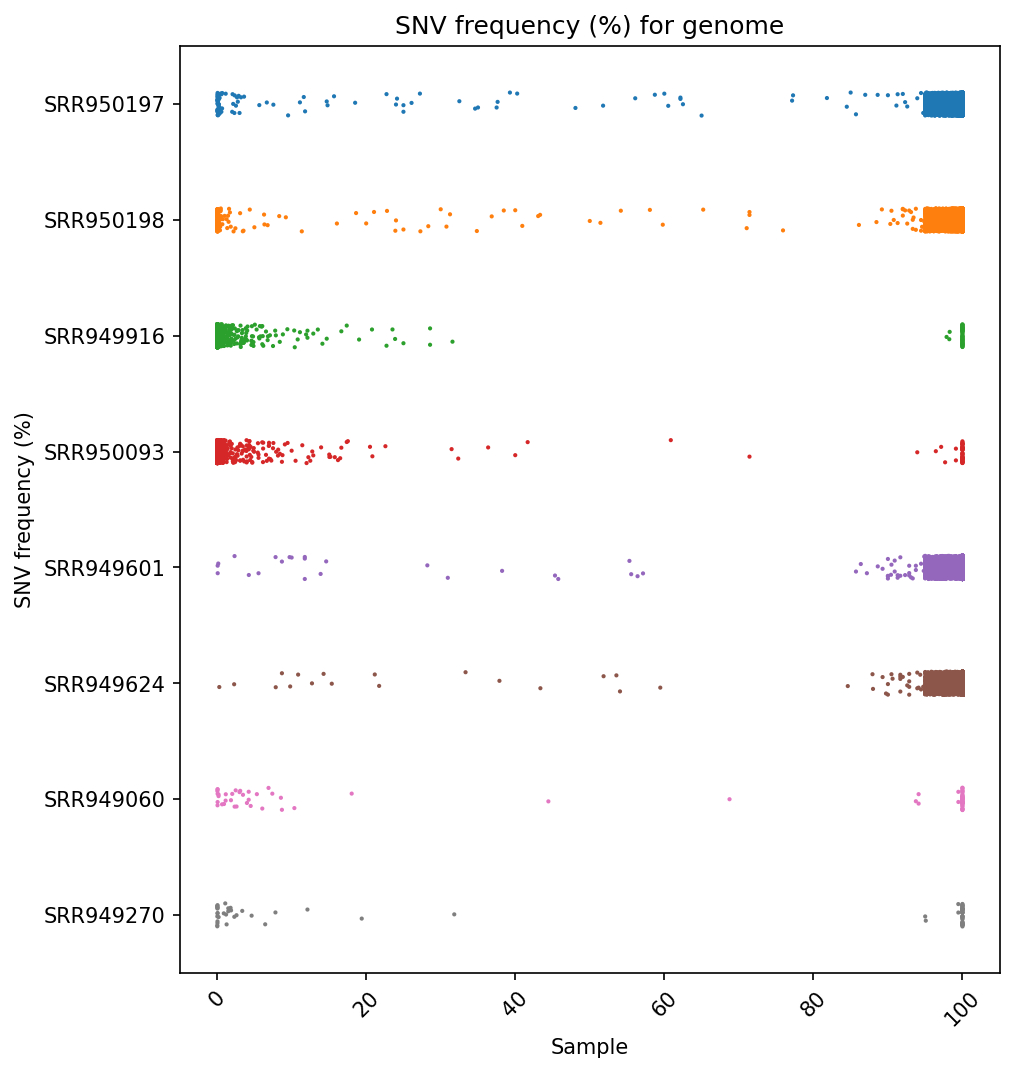
Frequency Per Sample Strip Plot
Each reference pathogen genome has its own frequency per sample strip plot. It plots a strip plot, where each dot is the frequency of an SNV, and it appears in the strip of their respective sample. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/common.frequencyPerRun.png for each reference genome graph.
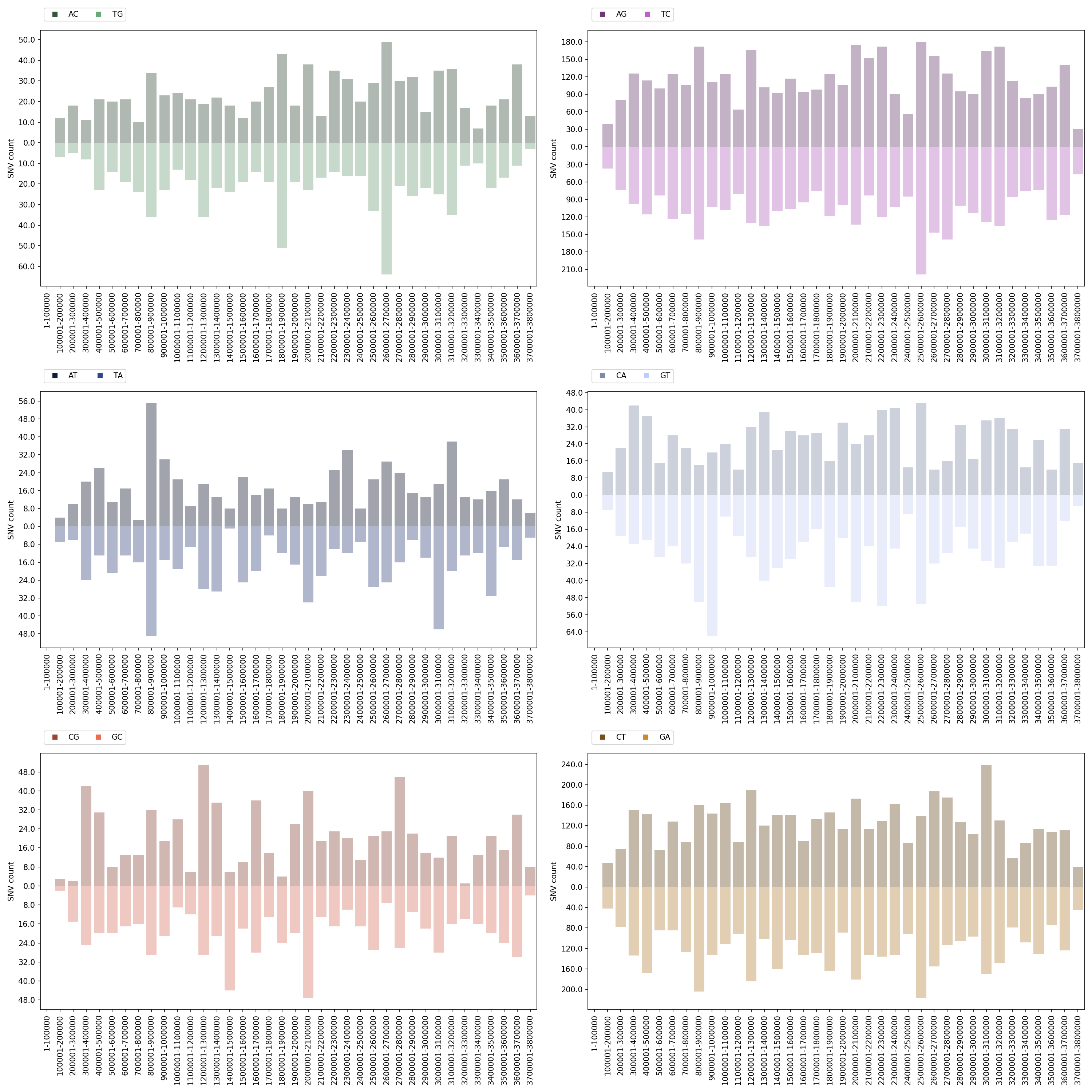
Distribution Histograms Plot
Each reference pathogen genome has its own distribution histograms plots. It plots six graphs in one file per chromosome/segment, where each graph represents a mutation (top half) and its reverse complement (bottom half). Each graph has a histogram displaying the number of SNVs of that mutation found each 100000 nucleotides with respect to the reference genome. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/CHROMOSOME_histogram.png for each chromosome/segment in each reference genome.
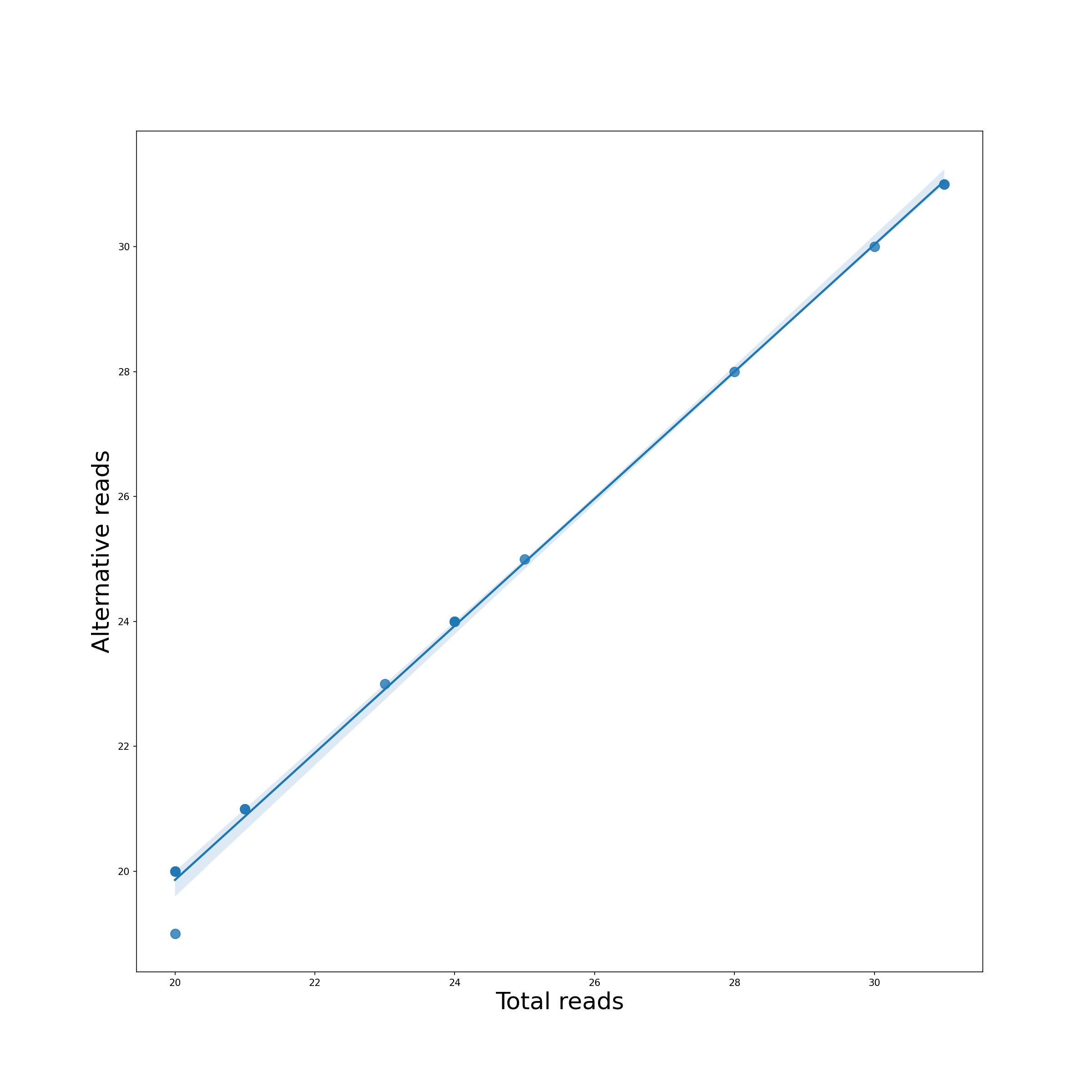
Regression Plot
Each reference pathogen genome has its own regression plots. It displays a dot plot of mutated (or alternate) reads vs the total reads per position. If it finds a suitable linear function, then it is also plotted. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/CHROMOSOME.regression.png for each chromosome/segment in each reference genome.
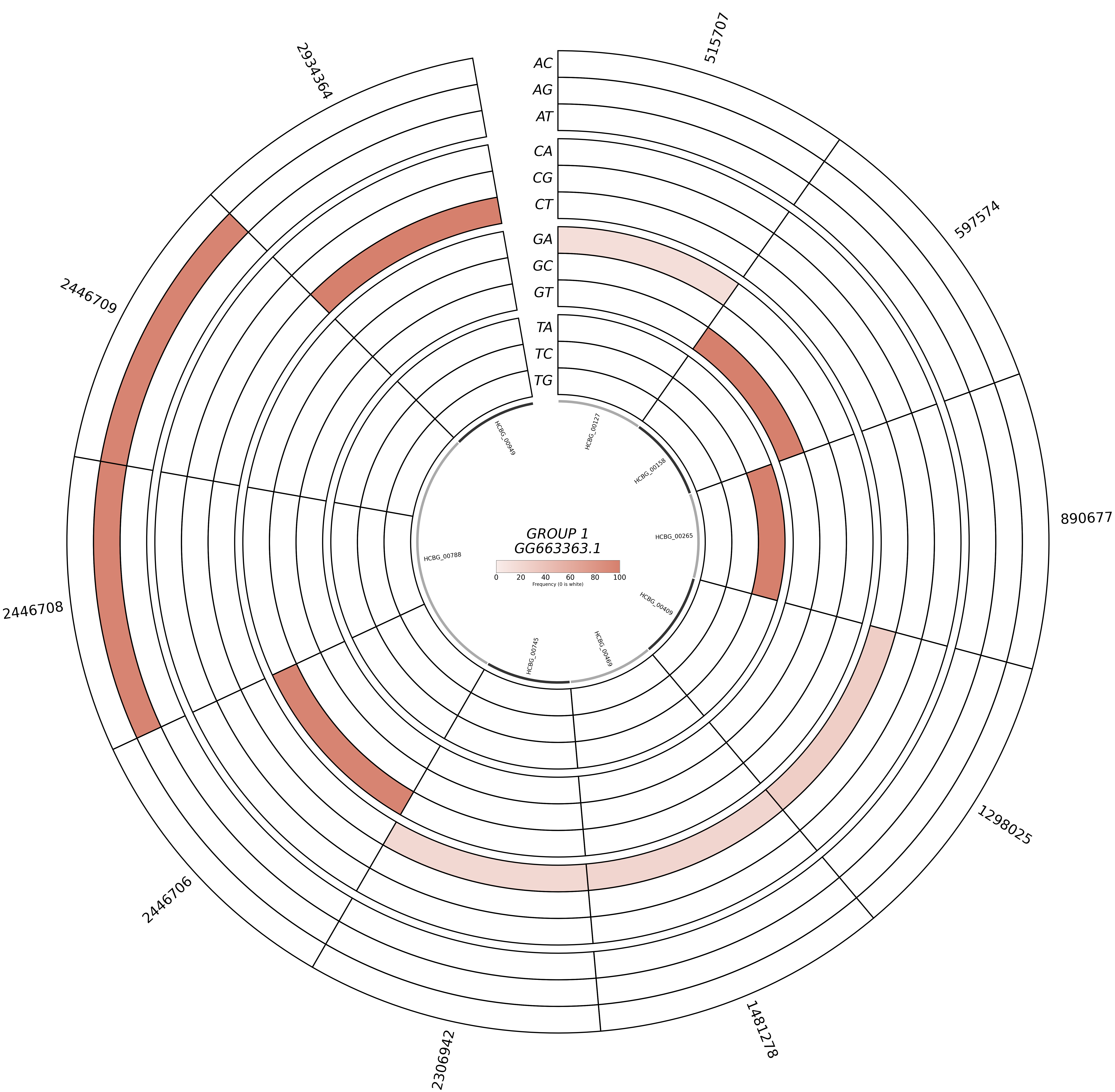
Presence Per Run Position Plot
Each reference pathogen genome has its own presence per run position plots as a circos graph and a heatmap.
The circos graph is a circular graph that displays a different position each arc, up to 150 positions, while each concentric strip at each radius level displays a different run, creating cells. The circos graph supports up to 20 samples. If a cell is colored, then it means that the corresponding position was mutated in that sample. If the graph contains multiple genes, the genes range will be displayed in the innermost circle strip. Because there is a limit on the positions that each circos graph can display, it is possible that there are multiple graphs for each sample or reference pathogen. Genes that have less than 150 mutated positions will be grouped with other genes that also have less than that number of mutated positions. If a gene has more than 150 mutated positions, it will be split in different files. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/circos/CHROMOSOME_GROUP.png for each group in each chromosome/segment per reference genome, or 6-visualization/REFERENCE_NAME/graphs/circos/GENE_GROUP.png for each group in each gene per reference genome.
The heatmap is a tabular graph where each column represents a sample, and each row represents a position in the reference chromosome/segment. Each heatmap can have up to 300 positions. If a cell is colored, then it means that the corresponding position was mutated in that sample. If the graph contains multiple genes, the genes range will be displayed to the right of the heatmap. Because there is a limit on the positions that each heatmap can display, it is possible that there are multiple graphs for each reference pathogen. Genes that have less than 300 mutated positions will be grouped with other genes that also have less than that number of mutated positions. If a gene has more than 300 mutated positions, it will be split in different files. These graphs were stored at 6-visualization/REFERENCE_NAME/graphs/heatmap/CHROMOSOME_GROUP.png for each group in each chromosome/segment per reference genome, or 6-visualization/REFERENCE_NAME/graphs/heatmap/GENE_GROUP.png for each group in each gene per reference genome.

Frequency Per Mutation Position Plot
Each sample has its own frequency per mutation position plots as a circos graph and a heatmap.
The circos graph is a circular graph that displays a different position each arc, up to 150 positions, while each concentric strip at each radius level displays a different mutation, creating cells. If a cell is colored, then it means that the corresponding position had that type of mutation, while the intensity of the color represents the frequency of that position-mutation. If the graph contains multiple genes, the genes range will be displayed in the innermost circle strip. Because there is a limit on the positions that each circos graph can display, it is possible that there are multiple graphs for each sample. Genes that have less than 150 mutated positions will be grouped with other genes that also have less than that number of mutated positions. If a gene has more than 150 mutated positions, it will be split in different files. These graphs were stored at 6-visualization/REFERENCE_NAME/SAMPLE_NAME/circos/CHROMOSOME_GROUP.png for each group in each chromosome/segment per sample, or 6-visualization/REFERENCE_NAME/SAMPLE_NAME/graphs/circos/GENE_GROUP.png for each group in each gene per sample.
The heatmap is a tabular graph where each column represents a sample, and each row represents a position in the reference chromosome/segment. Each heatmap can have up to 300 positions. If a cell is colored, then it means that the corresponding position had that type of mutation, while the intensity of the color represents the frequency of that position-mutation. If the graph contains multiple genes, the genes range will be displayed to the right of the heatmap. Because there is a limit on the positions that each heatmap can display, it is possible that there are multiple graphs for each sample or reference pathogen. Genes that have less than 300 mutated positions will be grouped with other genes that also have less than that number of mutated positions. If a gene has more than 300 mutated positions, it will be split in different files. These graphs were stored at 6-visualization/REFERENCE_NAME/SAMPLE_NAME/graphs/heatmap/CHROMOSOME_GROUP.png for each group in each chromosome/segment per sample, or 6-visualization/REFERENCE_NAME/SAMPLE_NAME/graphs/heatmap/GENE_GROUP.png for each group in each gene per sample.